Saurabh Saini

saurabh[dot]saini[at]research[dot]iiit[dot]ac[dot]in
About Me
I am finishing my Ph.D. (defense pending) under the guidance of Prof. P. J. Narayanan in Center for Visual Information Technology (CVIT) lab, a part of Kohli Center on Intelligent Systems (KCIS), at the International Institute of Information Technology-Hyderabad (IIIT-H) India.
My general research interest is in the topics related to Computer Vision, Machine Learning and Optimization, especially applied to 2D or 3D reconstruction.
Currently I am working on Inverse Rendering problems. Specifically, I am focusing on Intrinsic Image Decomposition (separating object property based vs. light related components in an image)
and Image Based Relighting (analyzing and editing image illumination).
Apart from this, I also like wandering in the domains of 3D modeling, registration, tracking, feature embedding, transfer learning, geometric learning, explainable AI etc. (the list grows ... :)
Personally, sometimes I enjoy sketching (graphite), reading (non-fiction) and writing (poems).
Publications

|
abstract |
bibtex |
arxiv |
webpage
Low Light Enhancement (LLE) is an important step to enhance images captured with insufficient light. Several local and global methods have been proposed over the years for this problem. Decomposing the image into multiple factors using an appropriate property is the first step in many LLE methods. In this paper, we present a new additive factorization that treats images to be composed of multiple latent specular components that can be estimated by modulating the sparsity during decomposition. We propose a model-driven learnable RSFNet framework to estimate these factors by unrolling the optimization into network layers. The factors are interpretable by design and can be manipulated directly for different tasks. We train our LLE system in a {\em zero-reference} manner without the need for any paired or unpaired supervision. Our system improves the state-of-the-art performance on standard benchmarks and achieves better generalization on multiple other datasets. The specularity factors can supplement other task specific fusion networks by inducing prior information for enhancement tasks like deraining, deblurring and dehazing with negligible overhead as shown in the paper.
|
|
abstract |
bibtex |
webpage |
code |
arxiv |
poster |
video
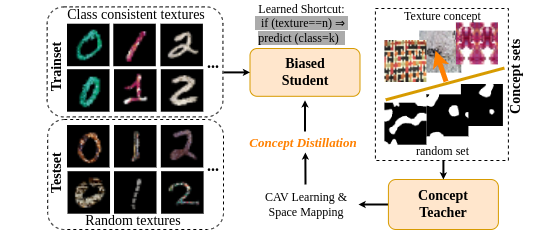
Humans use abstract concepts for understanding instead of hard features. Recent interpretability research has focused on human-centered concept explanations of neural networks. Concept Activation Vectors (CAVs) estimate a model's sensitivity and possible biases to a given concept. In this paper, we extend CAVs from post-hoc analysis to ante-hoc training in order to reduce model bias through fine-tuning using an additional Concept Loss. Concepts were defined on the final layer of the network in the past. We generalize it to intermediate layers using class prototypes. This facilitates class learning in the last convolution layer, which is known to be most informative. We also introduce Concept Distillation to create richer concepts using a pre-trained knowledgeable model as the teacher. Our method can sensitize or desensitize a model towards concepts. We show applications of concept-sensitive training to debias several classification problems. We also use concepts to induce prior knowledge into IID, a reconstruction problem. Concept-sensitive training can improve model interpretability, reduce biases, and induce prior knowledge. Please visit this https URL for code and more details.
|

|
abstract |
bibtex |
webpage |
code |
arxiv |
video
Radiance Fields (RF) are popular to represent casually-captured scenes for new view synthesis and several applications beyond it. Mixed reality on personal spaces needs understanding and manipulating scenes represented as RFs, with semantic segmentation of objects as an important step. Prior segmentation efforts show promise but do not scale to complex objects with diverse appearance. We present the ISRF method to interactively segment objects with fine structure and appearance. Nearest neighbor feature matching using distilled semantic features identifies high-confidence seed regions. Bilateral search in a joint spatio-semantic space grows the region to recover accurate segmentation. We show state-of-the-art results of segmenting objects from RFs and compositing them to another scene, changing appearance, etc., and an interactive segmentation tool that others can use.
|

|
abstract |
bibtex |
webpage |
code |
poster
Image Fusion maximizes the visual information at each pixel location by merging content from multiple images in order to produce an enhanced image. Exposure Fusion, specifically, fuses a bracketed exposure stack of poorly lit images to generate a properly illuminated image. Given a single input image, exposure fusion can still be employed on a ‘simulated’ exposure stack, leading to direct single image contrast and low-light enhancement. In this work, we present a novel ‘Quaternion Factorized Simulated Exposure Fusion’ (QFSEF) method by factorizing an input image into multiple illumination consistent layers. To this end, we use an iterative sparse matrix factorization scheme by representing the image as a two-dimensional pure quaternion matrix. Theoretically, our representation is based on the dichromatic reflection model and accounts for the two scene illumination characteristics by factorizing each progressively generated image into separate specular and diffuse components. We empirically prove the advantages of our factorization scheme over other exposure simulation methods by using it for the low-light image enhancement task.
|
|
*****[Best Paper Award]*****
abstract |
bibtex |
webpage |
code |
poster |
supplementary
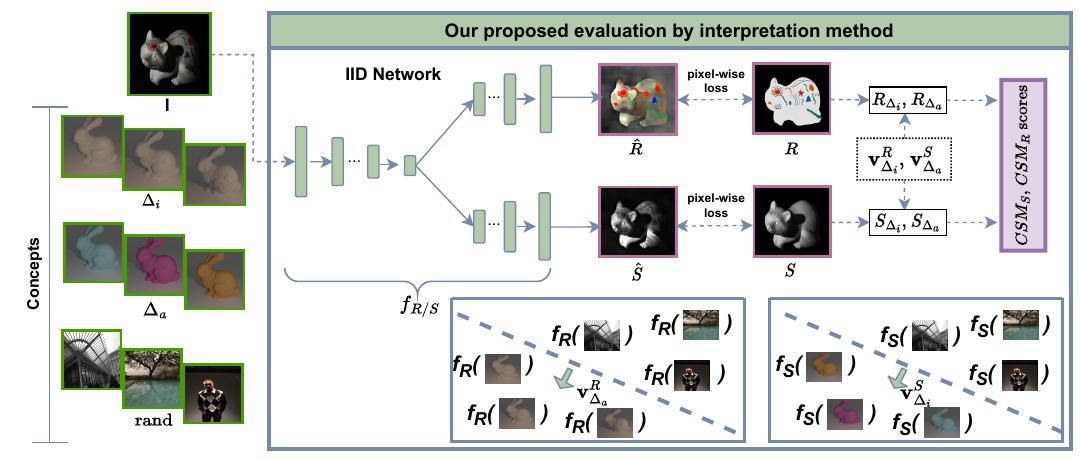
Evaluation of ill-posed problems like Intrinsic Image Decomposition (IID) is challenging. IID involves decomposing an image into its constituent illumination-invariant Reflectance (R) and albedo-invariant Shading (S) components. Contemporary IID methods use Deep Learning models and require large datasets for training. The evaluation of IID is carried out on either synthetic Ground Truth images or sparsely annotated natural images. A scene can be split into reflectance and shading in multiple, valid ways. Comparison with one specific decomposition in the ground-truth images used by current IID evaluation metrics like LMSE, MSE, DSSIM, WHDR, SAW AP %, etc. is inadequate. Measuring R-S disentanglement is a better way to evaluate the quality of IID. Inspired by ML interpretability methods, we propose Concept Sensitivity Metrics (CSM) that directly measure disentanglement using sensitivity to relevant concepts.
|

|
abstract |
bibtex |
webpage |
arxiv |
poster |
video
Stylized view generation of scenes captured casually using a camera has received much attention recently. The geometry and appearance of the scene are typically captured as neural point sets or neural radiance fields in the previous work. An image stylization method is used to stylize the captured appearance by training its network jointly or iteratively with the structure capture network. The state-of-the-art SNeRF method trains the NeRF and stylization network in an alternating manner. These methods have high training time and require joint optimization. In this work, we present StyleTRF, a compact, quick-to-optimize strategy for stylized view generation using TensoRF. The appearance part is finetuned using sparse stylized priors of a few views rendered using the TensoRF representation for a few iterations. Our method thus effectively decouples style-adaption from view capture and is much faster than the previous methods. We show state-of-the-art results on several scenes used for this purpose.
|

|
abstract |
bibtex |
webpage |
code |
arxiv (+ supplementary)
We tackle a 3D scene stylization problem — generating stylized images of a scene from arbitrary novel views given a set of images of the same scene and a reference image of the desired style as inputs. Direct solution of combining novel view synthesis and stylization approaches lead to results that are blurry or not consistent across different views. We propose a point cloud-based method for consistent 3D scene stylization. First, we construct the point cloud by back-projecting the image features to the 3D space. Second, we develop point cloud aggregation modules to gather the style information of the 3D scene, and then modulate the features in the point cloud with a linear transformation matrix. Finally, we project the transformed features to 2D space to obtain the novel views. Experimental results on two diverse datasets of real-world scenes validate that our method generates consistent stylized novel view synthesis results against other alternative approaches. |

|
abstract |
bibtex |
arxiv
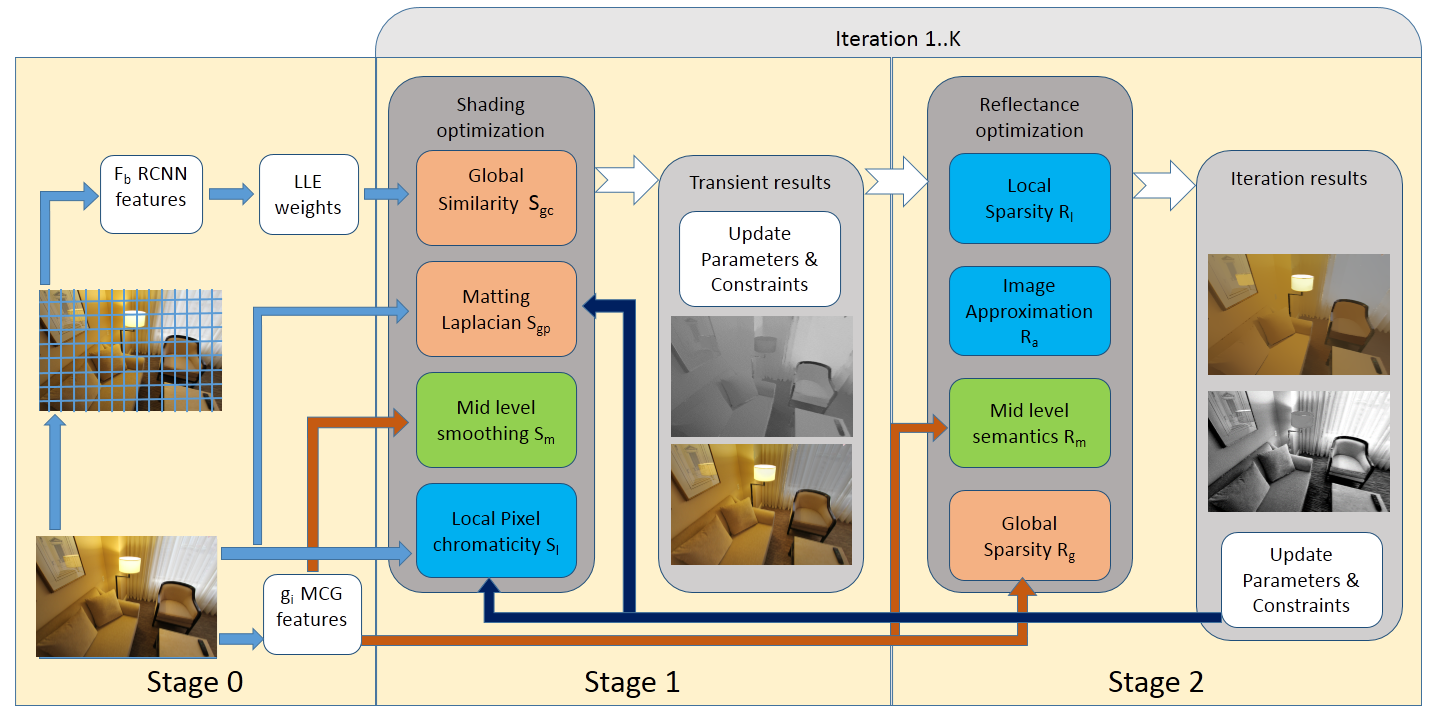
Intrinsic Image Decomposition (IID) is a challenging and interesting computer vision problem with various applications in several fields. We present novel semantic priors and an integrated approach for single image IID that involves analyzing image at three hierarchical context levels. Local context priors capture scene properties at each pixel within a small neighbourhood. Mid-level context priors encode object level semantics. Global context priors establish correspondences at the scene level. Our semantic priors are designed on both fixed and flexible regions, using selective search method and Convolutional Neural Network features. Our IID method is an iterative multistage optimization scheme and consists of two complementary formulations: L2 smoothing for shading and L1 sparsity for reflectance. Experiments and analysis of our method indicate the utility of our semantic priors and structured hierarchical analysis in an IID framework. We compare our method with other contemporary IID solutions and show results with lesser artifacts. Finally, we highlight that proper choice and encoding of prior knowledge can produce competitive results even when compared to end-to-end deep learning IID methods, signifying the importance of such priors. We believe that the insights and techniques presented in this paper would be useful in the future IID research. |

|
abstract |
bibtex |
webpage |
code |
arxiv
Photo realism in computer generated imagery is crucially dependent on how well an artist is able to recreate real-world materials in the scene. The workflow for material modeling and editing typically involves manual tweaking of material parameters and uses a standard path tracing engine for visual feedback. A lot of time may be spent in iterative selection and rendering of materials at an appropriate quality. In this work, we propose a convolutional neural network based workflow which quickly generates high-quality ray traced material visualizations on a shaderball. Our novel architecture allows for control over environment lighting and assists material selection along with the ability to render spatially-varying materials. Additionally, our network enables control over environment lighting which gives an artist more freedom and provides better visualization of the rendered material. Comparison with state-of-the-art denoising and neural rendering techniques suggests that our neural renderer performs faster and better. We provide a interactive visualization tool and release our training dataset to foster further research in this area. |
|
*****[Best Industrial Paper, Honourable Mention]*****
abstract |
bibtex |
pdf |
supplementary
Intrinsic Image Decomposition (IID) is a challenging and interesting computer vision problem with various applications in several fields. We present novel semantic priors and an integrated approach for single image IID that involves analyzing image at three hierarchical context levels. Local context priors capture scene properties at each pixel within a small neighborhood. Mid-level context priors encode object level semantics. Global context priors establish correspondences at the scene level. Our semantic priors are designed on both fixed and flexible regions, using selective search method and Convolutional Neural Network features. Experiments and analysis of our method indicate the utility of our weak semantic priors and structured hierarchical analysis in an IID framework. We compare our method with the current state-of-the-art and show results with lesser artifacts. Finally, we highlight that proper choice and encoding of prior knowledge can produce competitive results compared to end-to-end deep learning IID methods, signifying the importance of such priors. We believe that the insights and techniques presented in this paper would be useful in the future IID research. |
|
abstract |
bibtex |
webpage |
pdf |
supplementary |
presentation
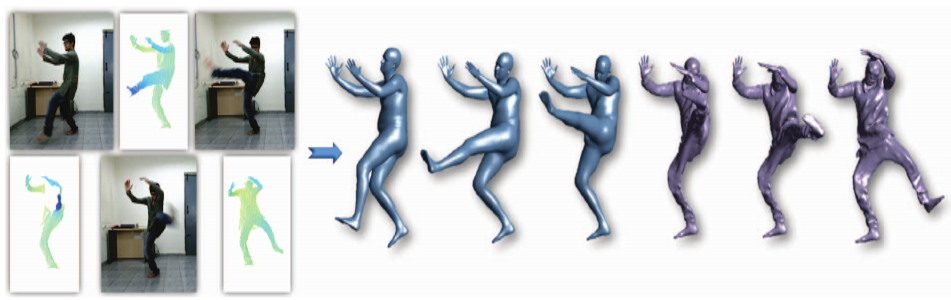
Human body tracking typically requires specialized capture set-ups. Although pose tracking is available in consumer devices like Microsoft Kinect, it is restricted to stick figures visualizing body part detection. In this paper, we propose a method for full 3D human body shape and motion capture of arbitrary movements from the depth channel of a single Kinect, when the subject wears casual clothes. We do not use the RGB channel or an initialization procedure that requires the subject to move around in front of the camera. This makes our method applicable for arbitrary clothing textures and lighting environments, with minimal subject intervention. Our method consists of 3D surface feature detection and articulated motion tracking, which is regularized by a statistical human body model. We also propose the idea of a Consensus Mesh (CMesh) which is the 3D template of a person created from a single view point. We demonstrate tracking results on challenging poses and argue that using CMesh along with statistical body models can improve tracking accuracies. Quantitative evaluation of our dense body tracking shows that our method has very little drift which is improved by the usage of CMesh. |

|
abstract |
bibtex |
code |
pdf |
supplementary
In this paper, we presents a novel method (RGBF-IID) for intrinsic image decomposition of a wild scene without any restrictions on the complexity, illumination or scale of the image. We use focal stacks of the scene as input. A focal stack captures a scene at varying focal distances. Since focus depends on distance to the object, this representation has information beyond an RGB image towards an RGBD image with depth. We call our representation an RGBF image to highlight this. We use a robust focus measure and generalized random walk algorithm to compute dense probability maps across the stack. These maps are used to define sparse local and global pixel neighbourhoods, adhering to the structure of the underlying 3D scene. We use these neighbourhood correspondences with standard chromaticity assumptions as constraints in an optimization system. We present our results on both indoor and outdoor scenes using manually captured stacks of random objects under natural as well as artificial lighting conditions. We also test our system on a larger dataset of synthetically generated focal stacks from NYUv2 and MPI Sintel datasets and show competitive performance against current state-of-the-art IID methods that use RGBD images. Our method provides a strong evidence for the potential of RGBF modality in place of RGBD in computer vision |

|
abstract |
bibtex |
arxiv
User-given tags or labels are valuable resources for semantic understanding of visual media such as images and videos. Recently, a new type of labeling mechanism known as hash-tags have become increasingly popular on social media sites. In this paper, we study the problem of generating relevant and useful hash-tags for short video clips. Traditional data-driven approaches for tag enrichment and recommendation use direct visual similarity for label transfer and propagation. We attempt to learn a direct low-cost mapping from video to hash-tags using a two step training process. We first employ a natural language processing (NLP) technique, skip-gram models with neural network training to learn a low-dimensional vector representation of hash-tags (Tag2Vec) using a corpus of ∼ 10 million hash-tags. We then train an embedding function to map video features to the low-dimensional Tag2vec space. We learn this embedding for 29 categories of short video clips with hash-tags. A query video without any tag-information can then be directly mapped to the vector space of tags using the learned embedding and relevant tags can be found by performing a simple nearest-neighbor retrieval in the Tag2Vec space. We validate the relevance of the tags suggested by our system qualitatively and quantitatively with a user study. |
|
abstract |
bibtex |
arxiv
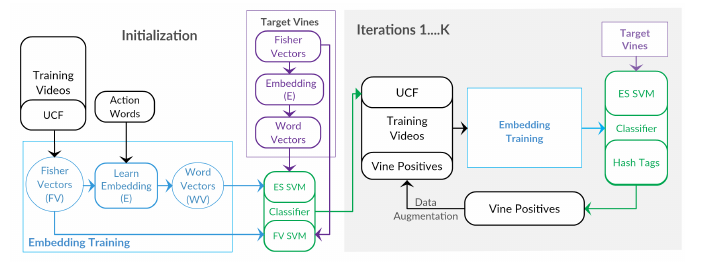
Short internet video clips like vines present a significantly wild distribution compared to traditional video datasets. In this paper, we focus on the problem of unsupervised action classification in wild vines using traditional la- beled datasets. To this end, we use a data augmentation based simple domain adaptation strategy. We utilize semantic word2vec space as a common subspace to embed video features from both, labeled source domain and unlabled target domain. Our method incrementally augments the labeled source with target samples and iteratively modifies the embedding function to bring the source and target distributions together. Additionally, we utilize a multi-modal representation that incorporates noisy semantic information available in form of hash-tags. We show the effectiveness of this simple adaptation technique on a test set of vines and achieve notable improvements in performance. |
Current Projects

|
|

|
|

|
|
